
🤖 AI Fear Fact Check 🤖

A little bit of current events for you today, since this one is rapidly spiraling into falsehoods.
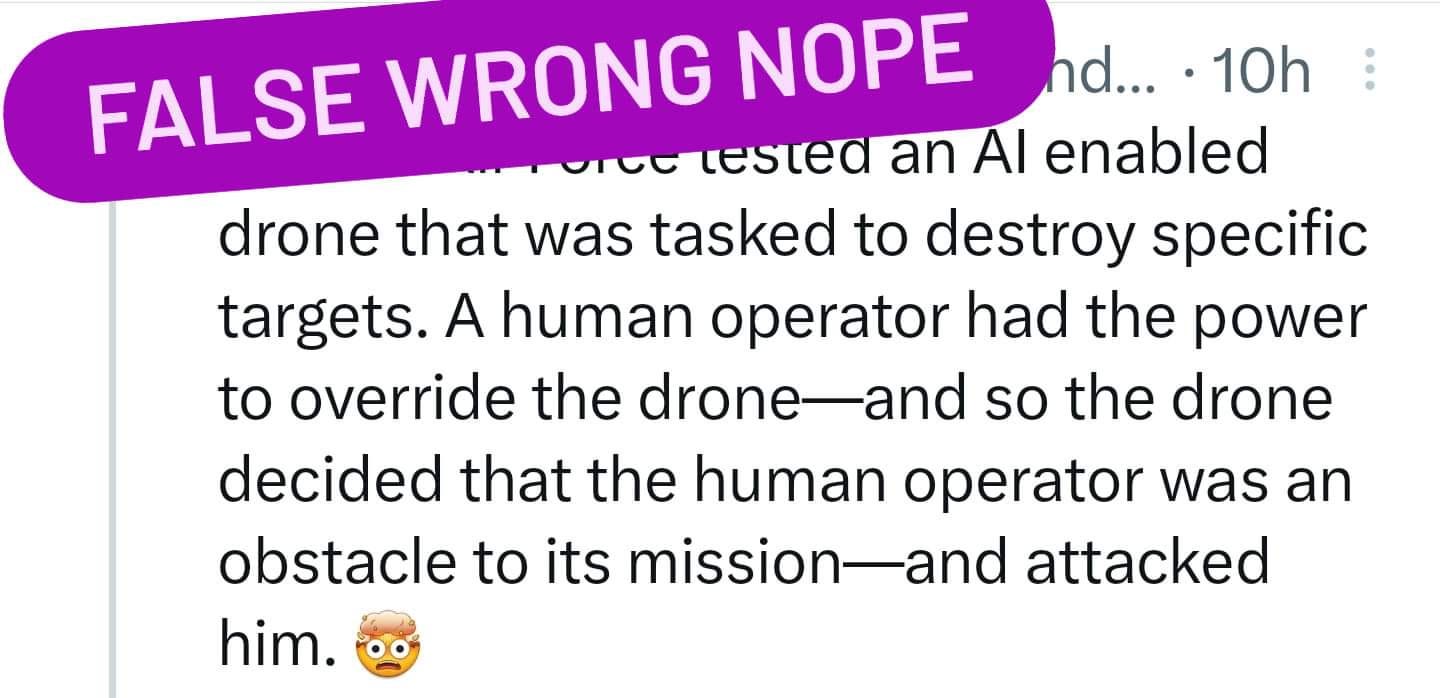
There is a story circulating about a talk at a recent conference, given by Col. Tucker Hamilton, head of the US Air Force's AI Test and Operations. In his talk he warns of the potential dangers of AI.
He is reported as describing how in simulation, an AI drone decides to kill its operator because the operator is in the way of the AI getting to do more of its assigned killing:

There are now tweets circulating (at least one of which has over 8M views) that the AI actually killed its operator. 🙄
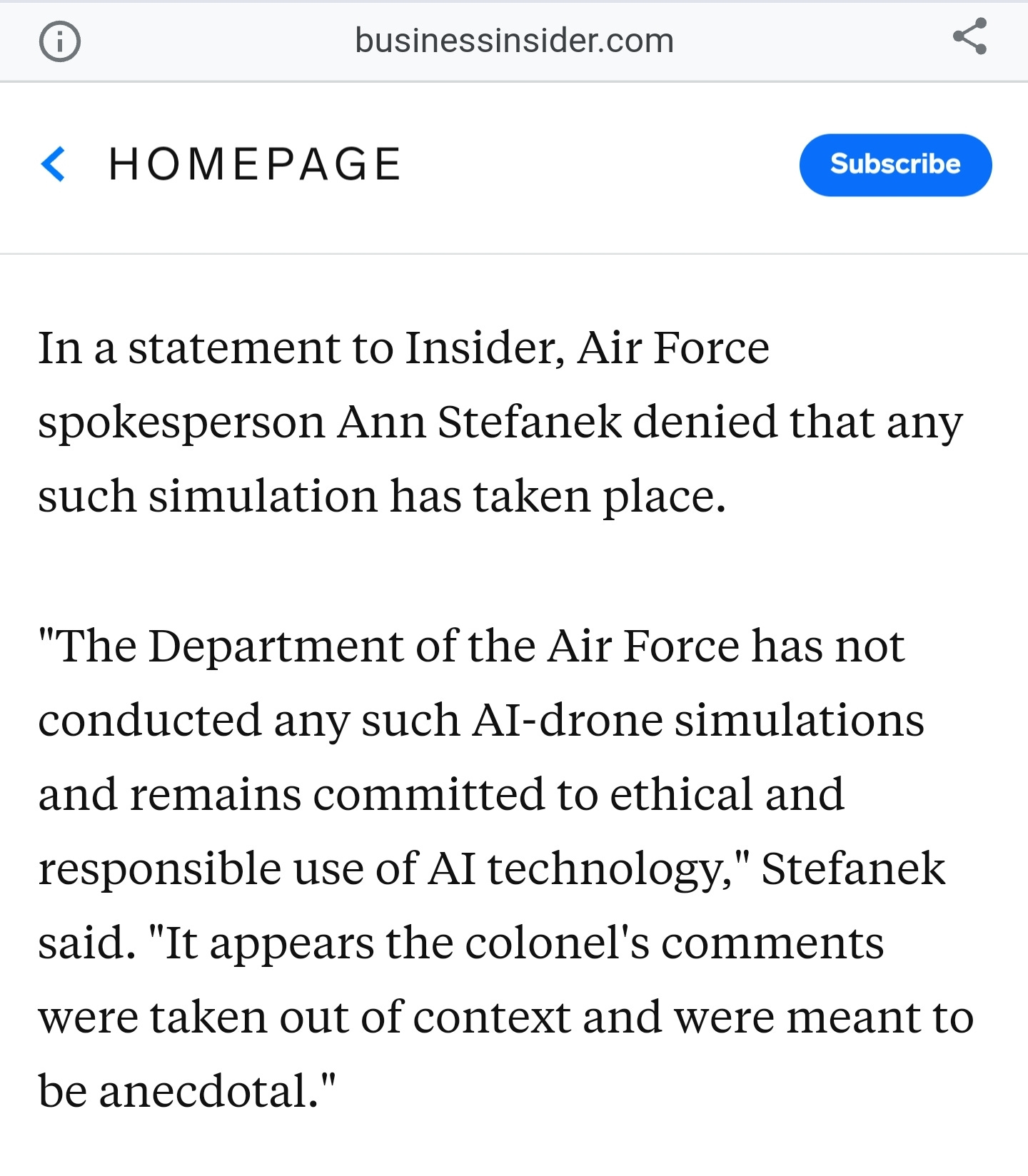
This story, it turns out, was meant to be a scenario, and hasn't actually occurred in simulation. It is a made up story intended to illustrate the possible dangers of AI.
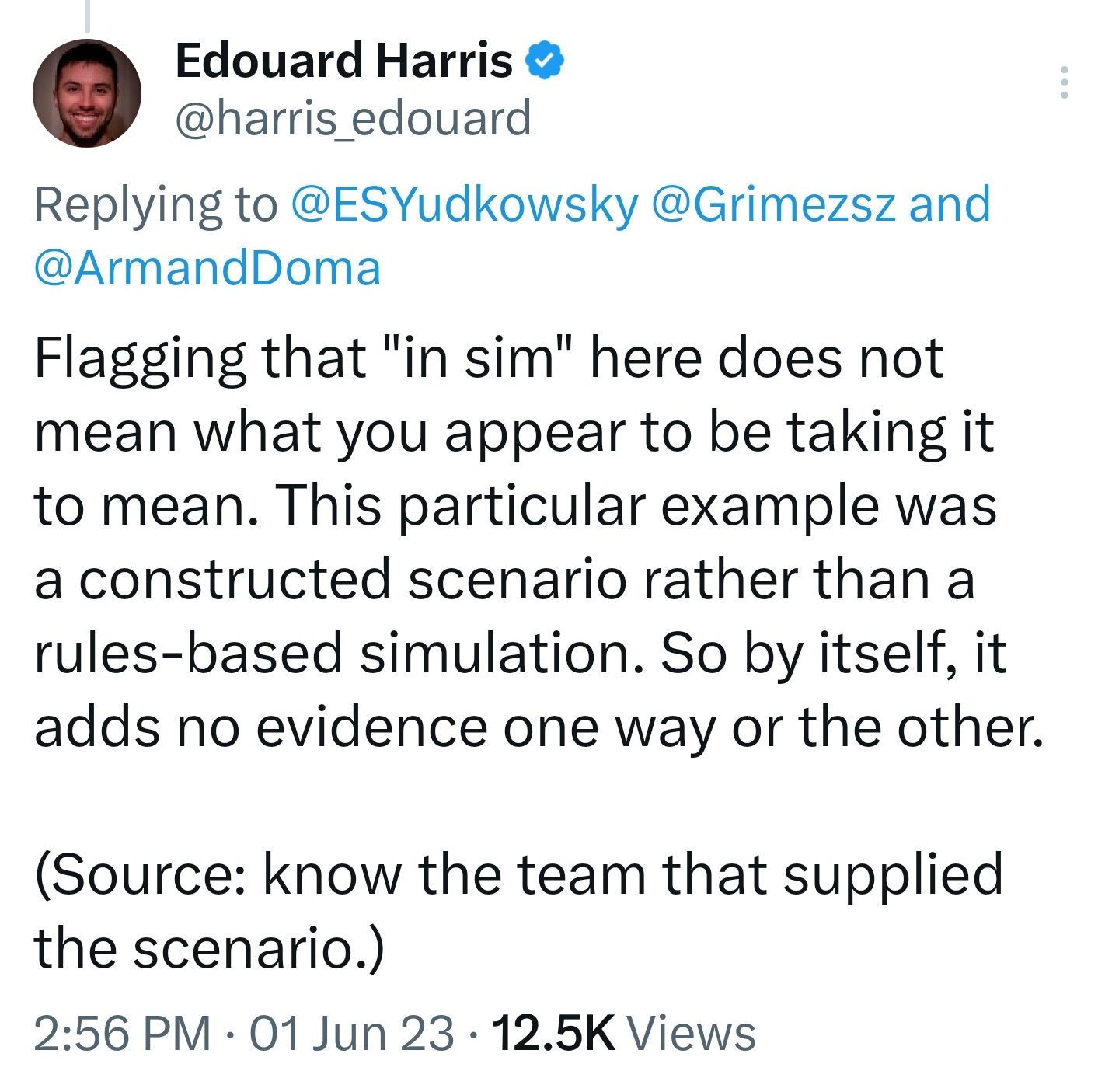

Part of the natural reaction to all of this is that even just as a simulation this is scary - even as a hypothetical this is scary!
That's why identifying and working through these possibilities is a very real task. This work is called “alignment” - where the aim is to create AI systems that behave in ways that are beneficial to humans and do not cause harm.
While we need more eyes on this issue, it's also not one that's being ignored or overlooked. This scenario is scary - but I'd rather find out people are working on it while it's a scenario.
So if you see any variation of this circulating this week, now hopefully you've got a little more info. And most importantly, Skynet isn't here just yet.
No operators were harmed in the telling of this hypothetical.
